The scenario
You’ve picked the right model for your email routing task. Everything works perfectly—emails get classified correctly, routed to the right teams, and your customers are happy. But then you notice something interesting in your logs: you’re spending more on input tokens than output tokens. The question worth asking is: does your prompt need to be that long?This is a very simple example illustrating the mechanism of A/B testing for LLMs. If you’re after something more
complex, check the other guides.
The hypothesis
Many developers write verbose, detailed prompts thinking more context equals better results. But for straightforward tasks like email classification, a shorter prompt might work just as well. Every word in your system prompt costs money—it’s sent with every single request. So there’s a good chance that a concise, direct prompt could deliver the same accuracy while cutting costs by reducing input tokens. But hunches aren’t enough, let’s test this hypothesis.Test configuration
This example shows a side-by-side comparison using the Narev Platform, testing two different prompts using the same model (gpt-oss-20b) on identical customer emails.
The only variable? The prompt style.
This creates a clean way to see how prompt length affects cost, speed, and accuracy.
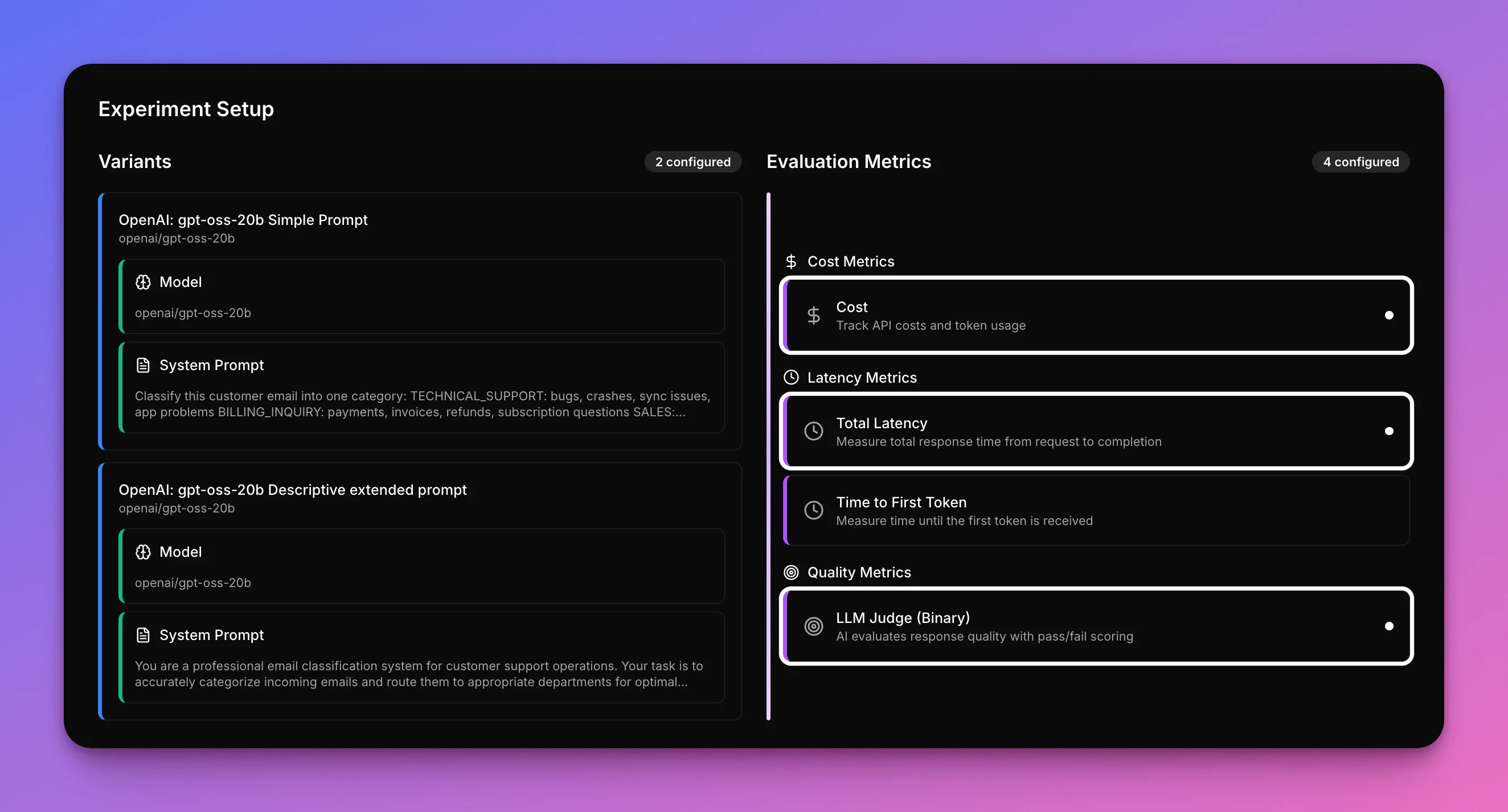
Prompts tested
Concise Prompt (225 tokens average):What gets measured
The test tracks three critical metrics for each prompt:- the cost per request (shorter prompts = fewer input tokens = lower costs)
- the speed of classification (measured by time to first token)
- the accuracy of the routing decisions (cheaper is only worth it if it still works)
Results
The results reveal something surprising: the verbose, “professional” prompt doesn’t just fail to improve accuracy—it’s actually worse on every metric. Both prompts achieve 100% accuracy on the test emails, but the concise prompt uses nearly half the input tokens and responds faster. The verbose prompt’s extra context and formatting doesn’t add value—it just burns tokens and slows things down.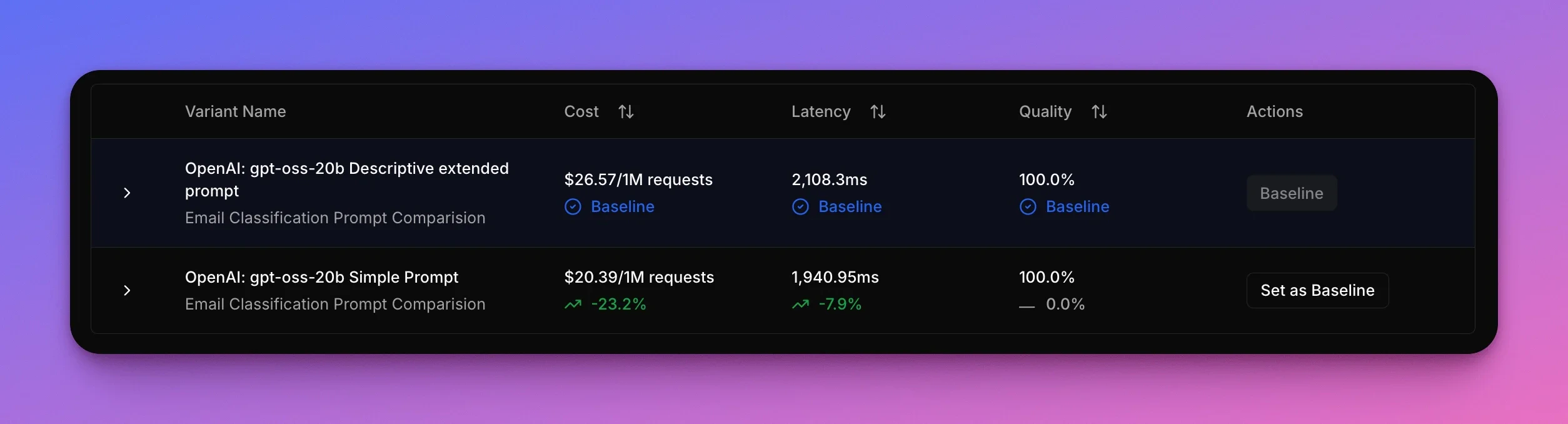
Winner for this test
The concise prompt wins decisively. It saves $6.18 per million requests (a 23% reduction) and responds 167 ms faster per request (8% faster) while maintaining 100% accuracy. There’s no tradeoff here—the simpler prompt is better in every way. The verbose prompt’s detailed categorization guidelines and analysis instructions don’t just waste money, they also slow down inference.Example in action
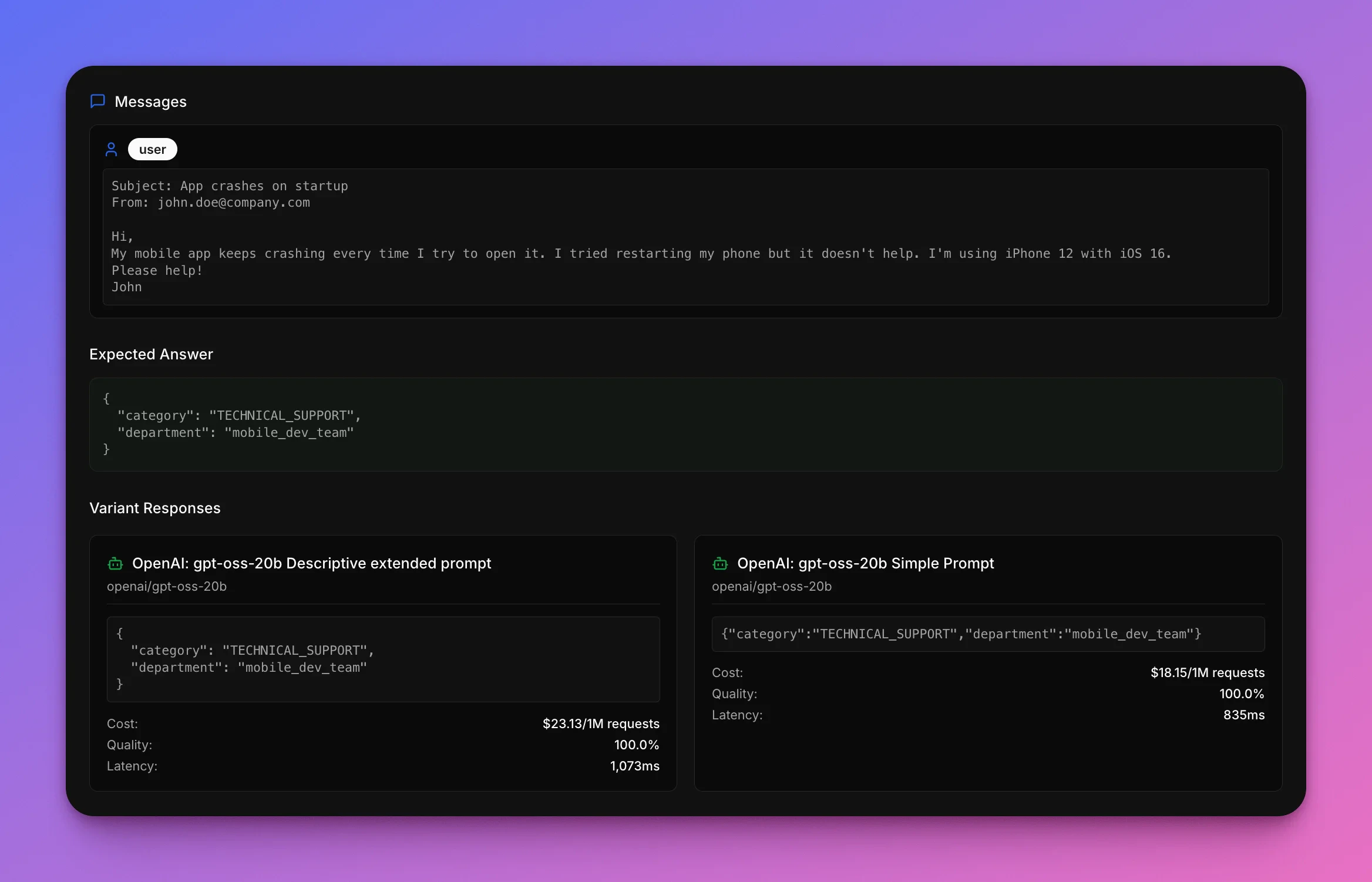
Look at how the prompts handle a typical sales inquiry. This is the kind of email that should be an easy win: clear enterprise sales intent, multiple specific questions, and an explicit request for a demo.Subject: Enterprise plan pricing
From: cto@fastgrowth.ioHi there,A 200-person company is looking to upgrade from its current solution. Could you send information about:
Mike Chen, CTO
From: cto@fastgrowth.ioHi there,A 200-person company is looking to upgrade from its current solution. Could you send information about:
- Enterprise plan features
- Volume discounts
- Implementation timeline
- API rate limits
Mike Chen, CTO
Sales team
How each prompt did
Good news: both prompts correctly route this email to sales. This example demonstrates that for straightforward cases (which make up the majority of customer emails), the concise prompt performs just as accurately. The verbose prompt’s detailed categorization guidelines and analysis instructions don’t add value—they just burn tokens and slow down inference.
What this shows
Prompt verbosity doesn’t equal better results. For straightforward tasks like email classification, a concise prompt is 23% cheaper and 8% faster while maintaining 100% accuracy. You don’t have to compromise anything. The simpler prompt wins on cost, speed, and quality—perfect classification that costs less and responds faster on every single request.The takeaway
Using a concise prompt saves 20.39 instead of $26.57 per million requests.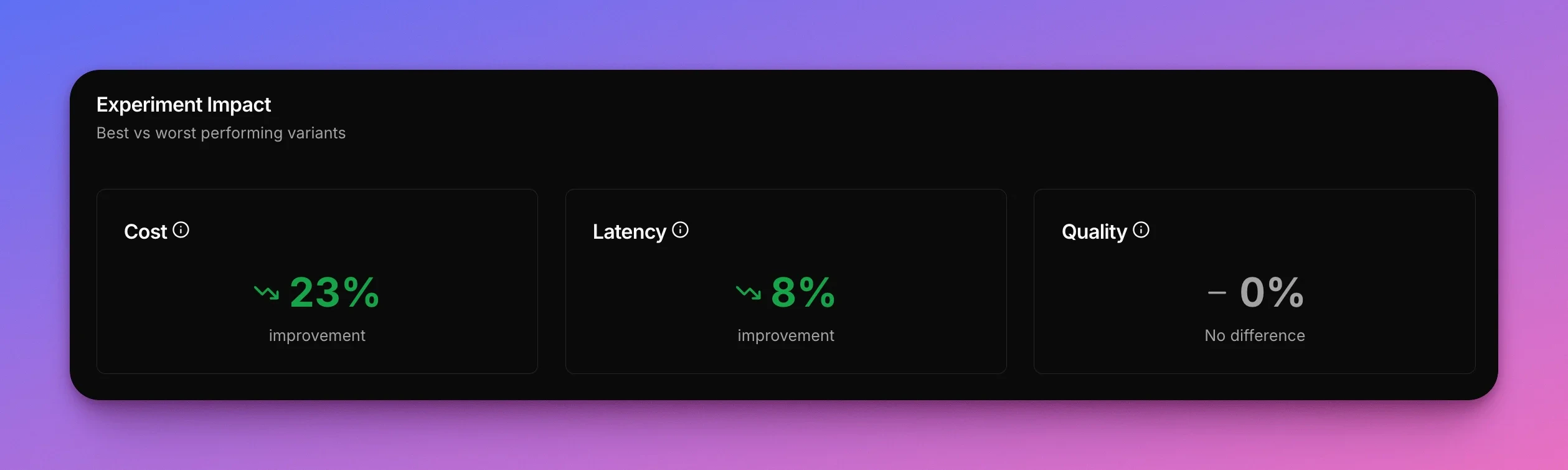
Want to test which prompt works best for your use case? Start testing for free →